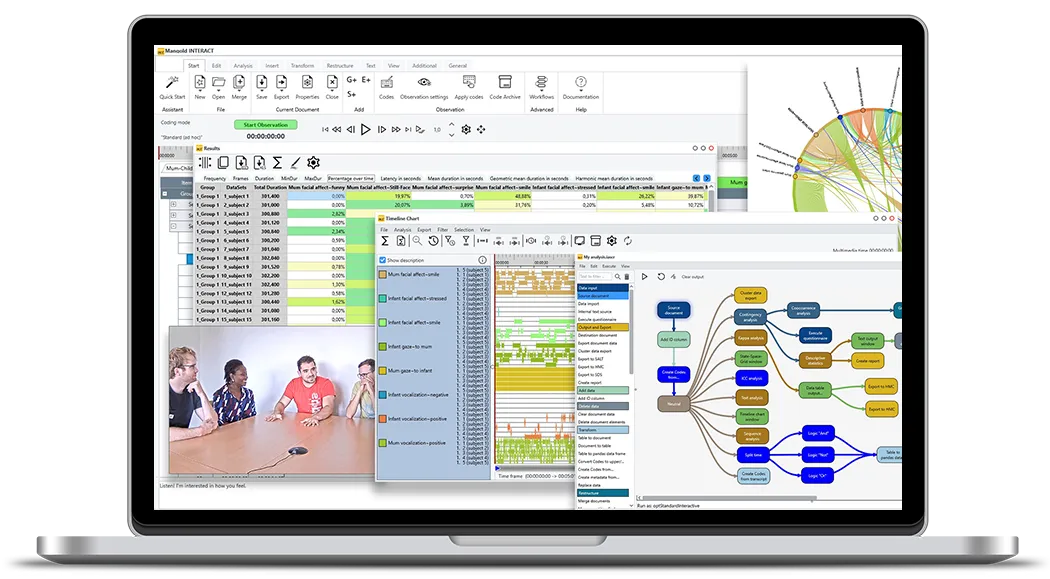
Tutorial · 8 min read
Gestik-Analyse leicht gemacht mit INTERACT
Erfahren Sie, wie Sie komplexe Gestik-Muster effizient mit der Mangold INTERACT Software analysieren, einschließlich mehrstufiger Kodiertechniken und ausgeklügelter Datenrestrukturierungsmethoden.

Eine detaillierte Gestik-Analyse besteht aus mehreren verschachtelten Ebenen, die nicht nur die Bewegung der aktiven Hand selbst, sondern auch spezifischere Details wie Struktur, Fokus und Funktion einer Bewegung angeben.
Um die gezeigten Schritte nachvollziehen zu können, müssen Sie mit dem Kodieren in Mangold INTERACT vertraut sein.
Wenn Sie jedoch nicht mit INTERACT vertraut sind, kann Ihnen dieser Artikel einen Einblick geben, wie einfach und leistungsstark die Datenerfassung und -analyse mit der INTERACT Software ist.
Kodierung einfacher Gesten und automatische Berechnung komplexer Gestenkombinationen aus diesen einfachen Ausgangsdaten.
Auf den ersten Blick scheint das Erfassen dieser Art von verschachtelten Informationen eine einfache Angelegenheit der lexikalischen Kodierung in INTERACT zu sein. Doch aufgrund der Art der Verschachtelung führt dieser Ansatz beim Kodieren zu einer riesigen Menge an doppelten Einträgen – was ihn weitaus zeitaufwändiger macht als nötig!
Dieser Artikel beschreibt, wie Sie die Datenerfassung vereinfachen können, indem Sie alle Ebenen separat erfassen (unter Verwendung des Kodierungsmodus ‘Standard’ und, wann immer möglich, sich gegenseitig ausschließender Codes).
Ziel
Detaillierte Ereignisse für alle Attribute einer Geste erstellen, ohne wiederholte Eingaben desselben Codes.
Lexikalische Kodierung ohne Ketten
Die größte Herausforderung, der wir hier begegnen, ist die Erfassung von mehrstufigen Codes, von denen einige unterschiedliche Dauern von der ursprünglichen Aktivierung haben können. Wir benötigen eine Methode, dies zu tun, ohne die Informationen der oberen Ebene jedes Mal neu eingeben zu müssen, wenn sich in einer dieser Ebenen eine winzige Änderung ergibt.
Eine Geste besteht aus einer Vielzahl von Dimensionen oder Attributen, wie z.B. welche Hand, welche Richtung, der Fokus, die Geschwindigkeit usw., was wie ein typischer Fall lexikalischer Kodierung klingt, bei der für jedes Attribut eine separate Ebene verwendet wird. Da sich jedoch alle Attribute, außer der Hand selbst, während dieser einen Geste ändern können, wäre das Erfassen mit lexikalischen Ketten viel zu umständlich.
Mit INTERACT können Sie jedes Attribut unabhängig erfassen und dennoch komplexe Ergebnisse generieren, die jede Bewegungsänderung mit einem einzigen Befehl spezifizieren.

So wird’s gemacht
Um die Bewegungen zu unterscheiden, werden die erforderlichen Gestik-Informationen zunächst in einem separaten DatenSet für jede Hand und Person gesammelt, aber sobald die Daten gesammelt sind, können Sie die verschiedenen Restrukturierungsroutinen nutzen, die in INTERACT verfügbar sind, um Ihre Ereignisse in kohärente Segmente umzuwandeln, die die genaue Struktur jedes Teils der Bewegung widerspiegeln. Schließlich können die Daten zu einem einzigen DatenSet pro Person zusammengeführt und für komplexe Analysen verwendet werden.
Beispiel Studiendesign
Dyadische Kommunikationen werden mit zwei Kameras aufgezeichnet, wobei jede Kamera auf einen Teilnehmer fokussiert ist.
Jede Hand wird separat beobachtet und jede Gestikebene wird in einem einzigen Durchgang kodiert, aber wenn Sie der Meinung sind, dass Sie zwei Ebenen gleichzeitig bearbeiten können, steht es Ihnen frei, dies zu tun.
Für eine einfachere Handhabung empfehlen wir, die Gestik-Daten in einer separaten Datendatei zu erfassen und die finalen, restrukturierten Daten erst am Ende des Prozesses mit den anderen Verhaltens-Ereignissen zusammenzuführen.
Kodierschema definieren
Wir erstellen Code-Definitionen für jede Ebene wie folgt:

Im ersten Durchgang können Sie, falls gewünscht, die Aktivierung beider Hände gleichzeitig erfassen. Diese Aktivierungs-Ereignisse decken die Gesamtdauer einer Bewegung ab, unabhängig von Änderungen in Struktur, Fokus oder Funktion während der Bewegung!
Zusätzliche Ebenen können natürlich implementiert werden, aber für dieses Beispiel ermöglicht uns das folgende 3-Ebenen-Setup, die Logik hinter dieser ausgeklügelten Methode zur einfachen Erfassung komplizierter Informationen zu zeigen und zu erklären:
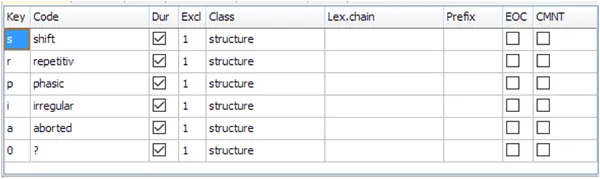
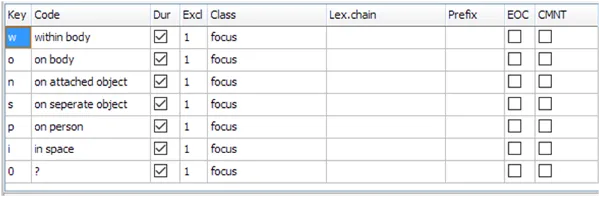
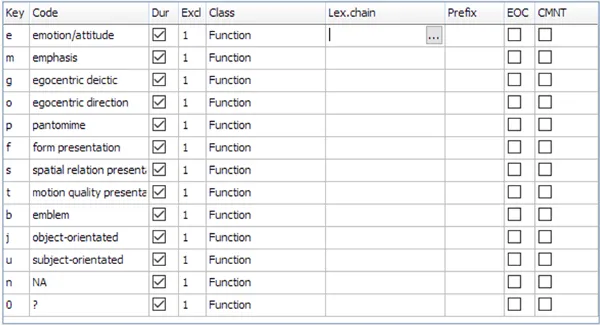
Vorbereitung der Gestik-Datenerfassung
Der hier erläuterte Ansatz nutzt den sehr cleveren Befehl Kodierungssegmente erstellen, um die benötigte Informationsstruktur zu erhalten, nachdem alle Daten gesammelt wurden.
Damit dies funktioniert, ist es wichtig, dass Sie die pro Hand gesammelten Informationen richtig auseinanderhalten können. Daher beginnen wir damit, die grundlegenden Handbewegungen in ein separates DatenSet pro Hand zu sammeln oder aufzuteilen:

Wenn Sie die Aktivierung pro Hand bereits kodiert haben, sollten Sie diese Ereignisse besser extrahieren und in separate Sets aufteilen, bevor Sie fortfahren.
TIPP: Wenn Sie die Aktivierung für beide Hände in einem Durchgang und somit innerhalb desselben DatenSets gesammelt haben, können Sie den Befehl Ereignisse mit identischen Codes in DataSets gruppieren verwenden, um die Aufteilung zu automatisieren!
Gestik-Beobachtungen erfassen
Sobald Sie die initialen Handbewegungen in separaten Sets pro Hand gesammelt/aufgeteilt haben, ist es an der Zeit, jede Bewegung im Detail zu analysieren.
Um die Struktur jeder Bewegung zu spezifizieren, öffnen Sie die Code-Definitionsdatei, die die ‘Struktur’-Codes enthält. Überprüfen Sie, ob der Kodierungsmodus ‘Standard’ aktiv ist und starten Sie den Beobachtungsmodus.
- Doppelklicken Sie auf ein ‘Aktivierungs’-Ereignis, um die Bewegung oder die betreffende Hand zu beobachten, damit Sie wissen, welche Struktur für den ersten Teil der Bewegung erforderlich ist.
- Doppelklicken Sie auf den Startzeitpunkt (onset) dieses Ereignisses, um das Video genau dort zu positionieren, sodass Sie diese Zeitinformation für den Start Ihres ersten ‘Struktur’-Ereignisses nutzen können.
- Klicken Sie auf den ‘Struktur’-Code, der für den ersten Teil der Bewegung gilt, und doppelklicken Sie erneut auf das ‘Aktivierungs’-Ereignis, um dieses Ereignis wiederzugeben. TIPP: Reduzieren Sie die Wiedergabegeschwindigkeit für mehr Genauigkeit.
- In dem Moment, in dem sich die Struktur der Bewegung ändert, klicken Sie auf den Struktur-Code, der zum zweiten Teil der Bewegung passt.
Aufgrund der in den Code-Definitionen festgelegten Ausschlusslisten wird das vorherige Struktur-Ereignis automatisch geschlossen, sobald das neue Struktur-Ereignis gestartet wird.
Solange Sie das Video nicht manuell anhalten, endet die Wiedergabe, sobald der Endzeitpunkt (offset) des Aktivierungs-Ereignisses erreicht ist. In dem Moment, in dem Sie das Video anhalten, funktioniert dies nicht mehr, bis Sie das Ereignis erneut doppelklicken.
- Um das letzte ‘Struktur’-Ereignis der ersten Bewegung zu schließen, klicken Sie auf den aktuell geöffneten Struktur-Code.
TIPP: Wenn Sie sicher sind, dass das aktuelle Struktur-Ereignis bis zum Ende der Bewegung dauert, müssen Sie nicht warten, bis das Ende des ausgewählten Ereignisses erreicht ist: Doppelklicken Sie auf den Endzeitpunkt (offset) des ‘Aktivierungs’-Ereignisses und klicken Sie auf den aktuell geöffneten ‘Struktur’-Code, um ihn zu schließen.
- Wiederholen Sie diese Schritte für jedes Aktivierungs-Ereignis für beide Hände.
- Wenn Sie fertig sind, beenden Sie die Beobachtungssitzung, BEVOR Sie die ‘Fokus’-Codes im Code-Definitionsfenster öffnen.
Für die Kodierung dieser Fokus-Ebene, sowie jeder der nächsten Ebenen, können Sie entscheiden, ob Sie das initiale ‘Aktivierungs’-Ereignis erneut abspielen möchten, wie beschrieben, oder ob Sie sich auf die in der vorherigen Runde erstellten Ereignisse konzentrieren müssen – in diesem Fall die ‘Struktur’-Ereignisse.
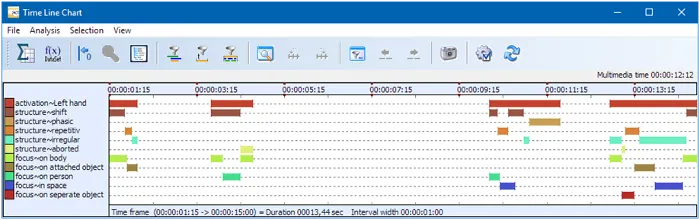
Zeitdiagramm
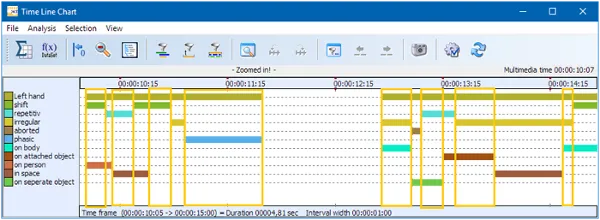
Nachdem Sie die Kodierung abgeschlossen haben, enthält Ihre Datendatei für jede Hand Daten wie diese, wie hier im Zeitdiagramm-Fenster von INTERACT zu sehen.
Rufen Sie die Funktion ‘Deskriptive Statistik’ in INTERACT auf, und diese wird Ihnen Informationen über die Häufigkeit von Bewegungen, die Gesamtdauer dieser Bewegungen usw. pro Hand liefern.
Ähnlich für alle Struktur-, Fokus- und Funktionscodes, unabhängig von ihrer Kombination.
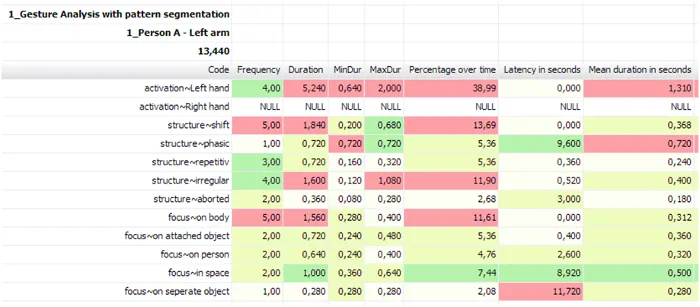
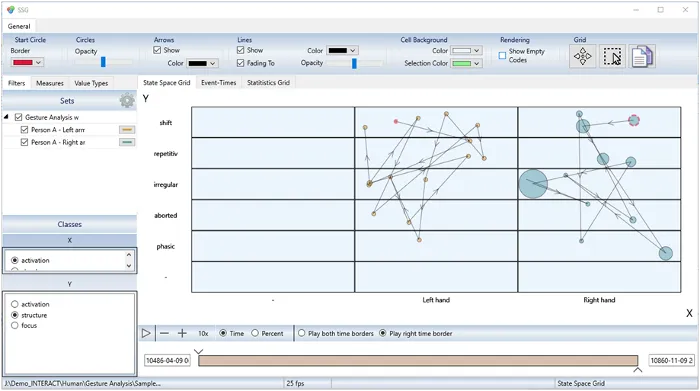
Co-occurrences visualisieren
Die Visualisierung der gesammelten Handbewegung pro Hand mithilfe des State-Space-Grid kann Ihnen ebenfalls einen interessanten Einblick ermöglichen, abhängig von den ausgewählten Klassen.
Jede Hand hat eine andere Farbe und die Zellen zeigen Ihnen die gleichzeitig auftretenden Situationen für zwei Klassen an:
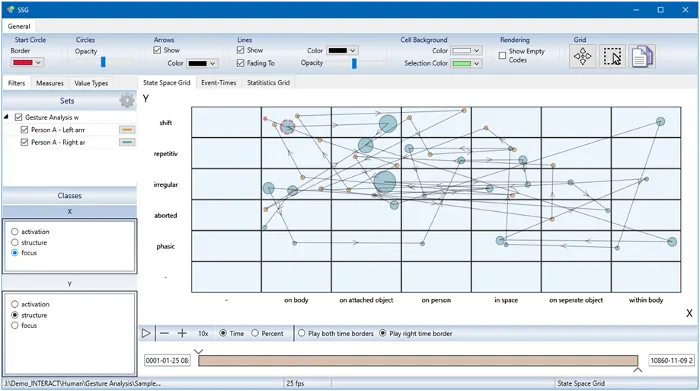
Kombinierte Gestik-Muster extrahieren
Um jedoch Details zu Kombinationen von mehr als zwei Ebenen zu erhalten, müssen wir die Daten neu strukturieren, indem wir einige clevere Routinen nutzen, die INTERACT zu bieten hat.
Bisher haben wir Daten für die verschiedenen Detailebenen jeder Bewegung unabhängig gesammelt. Nun möchten wir Ereignisse extrahieren, die jedes aufgetretene Gestik-Muster (jede Kombination aus Aktivierung, Struktur, Fokus und Funktion) repräsentieren.
Das bedeutet, dass jedes Mal, wenn sich Struktur, Fokus oder Funktion während einer Bewegung geändert haben, dies als eine andere Art von Bewegung betrachtet und somit durch ein Ereignis repräsentiert werden sollte, das alle diese gleichzeitig auftretenden Codes enthält:
Das Extrahieren dieser Informationen, basierend auf den Daten, die in einem DatenSet pro Hand strukturiert sind, erfordert nur einen einzigen Mausklick:
Wählen Sie den Befehl Kodierungssegmente erstellen, um eine neue Datendatei zu erstellen, die nun völlig neue Ereignisse enthält, von denen jedes die genaue Sequenz repräsentiert, die die aktuelle Kombination aus Struktur, Fokus und Funktion jeder Bewegung enthält:
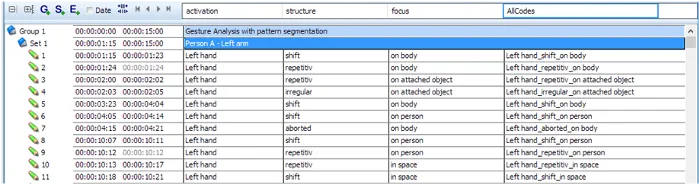
Diese Daten sehen nun aus, als wären sie lexikalisch kodiert worden.
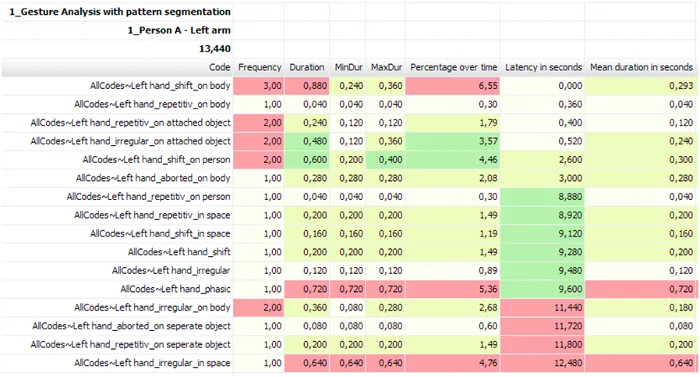
Für die Analyse ist insbesondere die neue Klasse ‘AllCodes’ von Interesse, da diese uns die Informationen über alle gleichzeitig auftretenden Kombinationen liefert:
Ereignisse beider Hände zusammenführen
Nun kann jedes Ereignis mühelos identifiziert werden, daher ist es Zeit, die Ereignisse beider Hände zusammenzuführen, zumindest wenn Sie spezifische Co-occurrences zwischen Händen finden möchten: Wählen Sie die Restrukturierungsfunktion Alle DataSets in einer neuen Datei kombinieren, um die Ereignisse aller DataSets pro DataGroup zusammenzuführen.
Analyse
Um alle Instanzen zu finden, bei denen beide Hände gleichzeitig aktiv waren, können Sie nun einfach den Co-occurrence-Filter auf die beiden Aktivierungs-Codes ‘Linke Hand’ und ‘Rechte Hand’ anwenden.
Um Co-occurrences bei spezifischen Bewegungsarten zu finden, müssen Sie möglicherweise neue Kombinationsklassen erstellen, ähnlich der ‘AllCodes’-Klasse. Wenn Sie beispielsweise an Situationen interessiert sind, in denen beide Hände mit demselben Fokus bewegt wurden, unabhängig von der Struktur oder Funktion, müssen Sie den Befehl Codes verschieben & kombinieren ausführen, um einen kombinierten Code nur für die Klassen ‘Aktivierung’ und ‘Fokus’ zu erstellen.
Die vollständigen Segmente, der Co-occurrence-Filter sollte am besten auf die Klasse ‘AllCodes’ angewendet werden.
Ihr Vorteil mit INTERACT
Erfassen Sie so viele Dimensionen, wie Sie benötigen, und fügen Sie jederzeit neue Dimensionen hinzu, um die Originaldaten zu erweitern. Erhalten Sie Statistiken pro Dimension und erstellen Sie sofort neue Ereignisse für jede Kombination überlappender Aktionen.
Überprüfen Sie pro Dimension oder pro kombinierter Aktion, je nach Ihren Bedürfnissen.
Einer der größten Vorteile von INTERACT ist seine Flexibilität und die Fähigkeit, gesammelte Daten zu reorganisieren, umzubenennen und zu verschieben, falls Sie feststellen, dass Ihre anfängliche Struktur nicht perfekt ist, um die Antworten zu finden, nach denen Sie suchen.
INTERACT: Eine Software für Ihren gesamten Forschungs-Workflow
Von der Datenerfassung bis zur Analyse – einschließlich GSEQ-Integration – INTERACT deckt alles ab.